
# 效率-私有化部署
# 私有化部署工具
详细信息可访问AI类-开发框架 (opens new window)
# 模型工具
# UI工具
- Lobe Chat (opens new window) 一个国内开源的LLM WebUI框架
- Open WebUI (opens new window) 一个支持各种LLM(大型语言模型)运行器,包括Ollama和兼容OpenAI的API。
# DeepSeek R1部署相关
# DeepSeek R1 模型
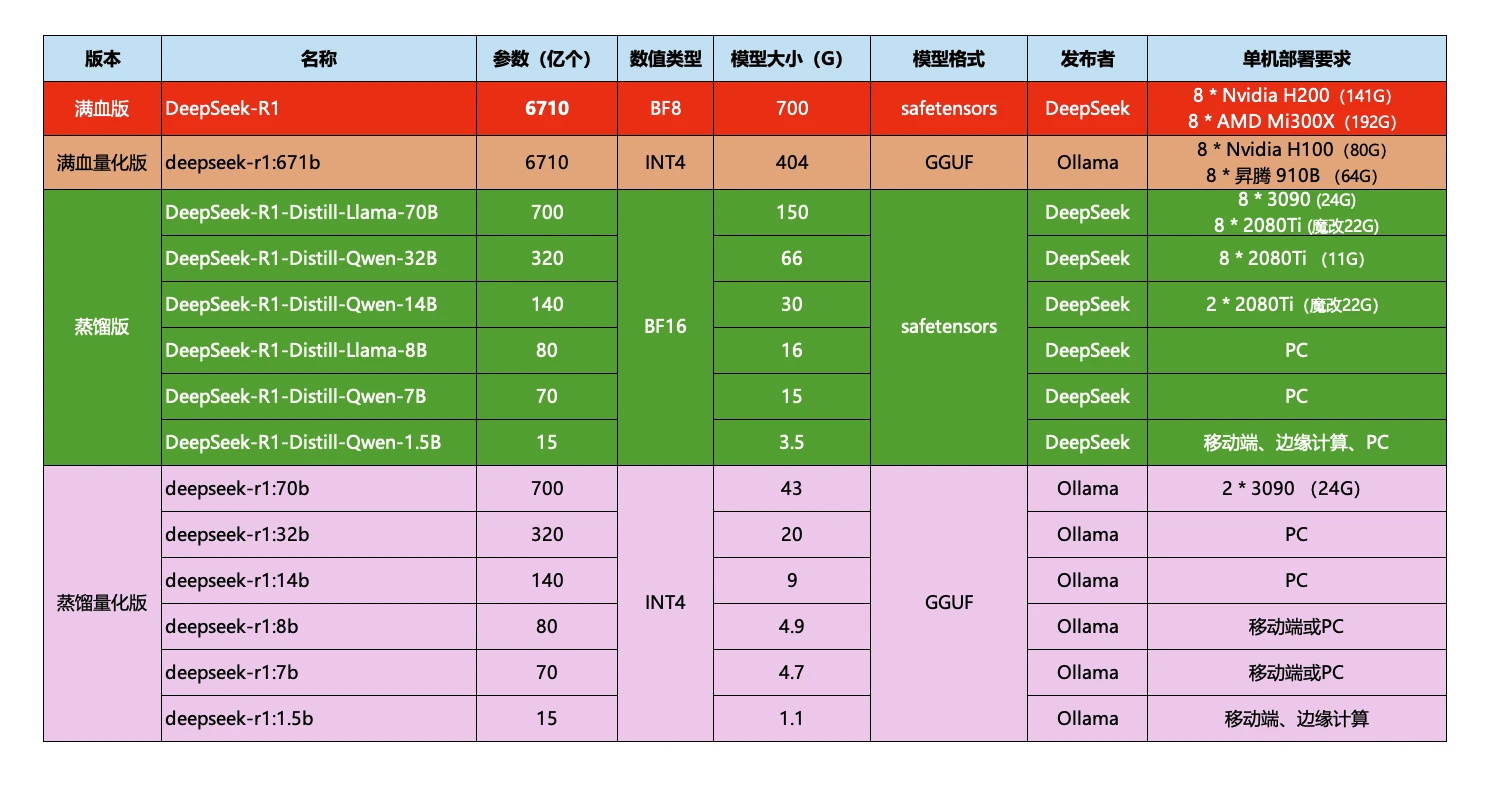
# 版本区别:
- 满血版:数规模最大的版本
- 蒸馏版:参数规模较小,从1.5B到32B不等,具体取决于蒸馏的程度12。也有说法是提供1.5B/7B/8B/14B/32B/70B等多尺寸模型
- 量化版:基于蒸馏版或满血版进行量化,参数规模保持不变,但通过降低模型参数的精度来减少计算资源消耗
# 数值类型
FP16 和 BF16 都是16位浮点数格式,用于加速深度学习模型的训练和推理过程。DeepSeek 满血版使用的是 BF16(Brain Floating Point 16) 数值格式
FP16:适合对精度要求不高但需要减少内存占用和计算量的场景。BF16:适合需要处理大范围数值且对数值稳定性要求较高的场景。
| 特性 | FP16 | BF16 |
|---|---|---|
| 符号位 | 1 位 | 1 位 |
| 指数位 | 5 位 | 8 位 |
| 尾数位 | 10 位 | 7 位 |
| 精度 | 较高 | 较低 |
| 动态范围 | 较小 | 较大 |
| 数值稳定性 | 较低 | 较高 |
| 应用场景 | 深度学习训练和推理 | 深度学习训练,特别是大范围数值处理 |
# 模型格式
模型格式 safetensors 和 GGUF 两种格式区别
safetensors: 是一种安全的模型格式,专门设计用于避免传统格式(如 PyTorch 的 .pt 或 .bin)中可能存在的反序列化漏洞。GGUF: 是一种轻量级的模型格式,专门设计用于本地部署,适合资源受限设备。
| 特性 | safetensors | GGUF |
|---|---|---|
| 安全性 | 高,避免反序列化漏洞 | 依赖量化工具的安全性 |
| 加载速度 | 快,支持内存映射 | 快,量化后加载更快 |
| 内存占用 | 较低,但不如量化模型 | 极低,适合资源受限设备 |
| 兼容性 | 广泛支持(Hugging Face 等) | 主要用于 llama.cpp 生态 |
| 文件大小 | 与传统格式相当 | 显著小于原始模型 |
| 主要用途 | 安全高效加载,通用场景 | 本地部署,资源受限设备 |
# DeepSeek R1 各版本区别
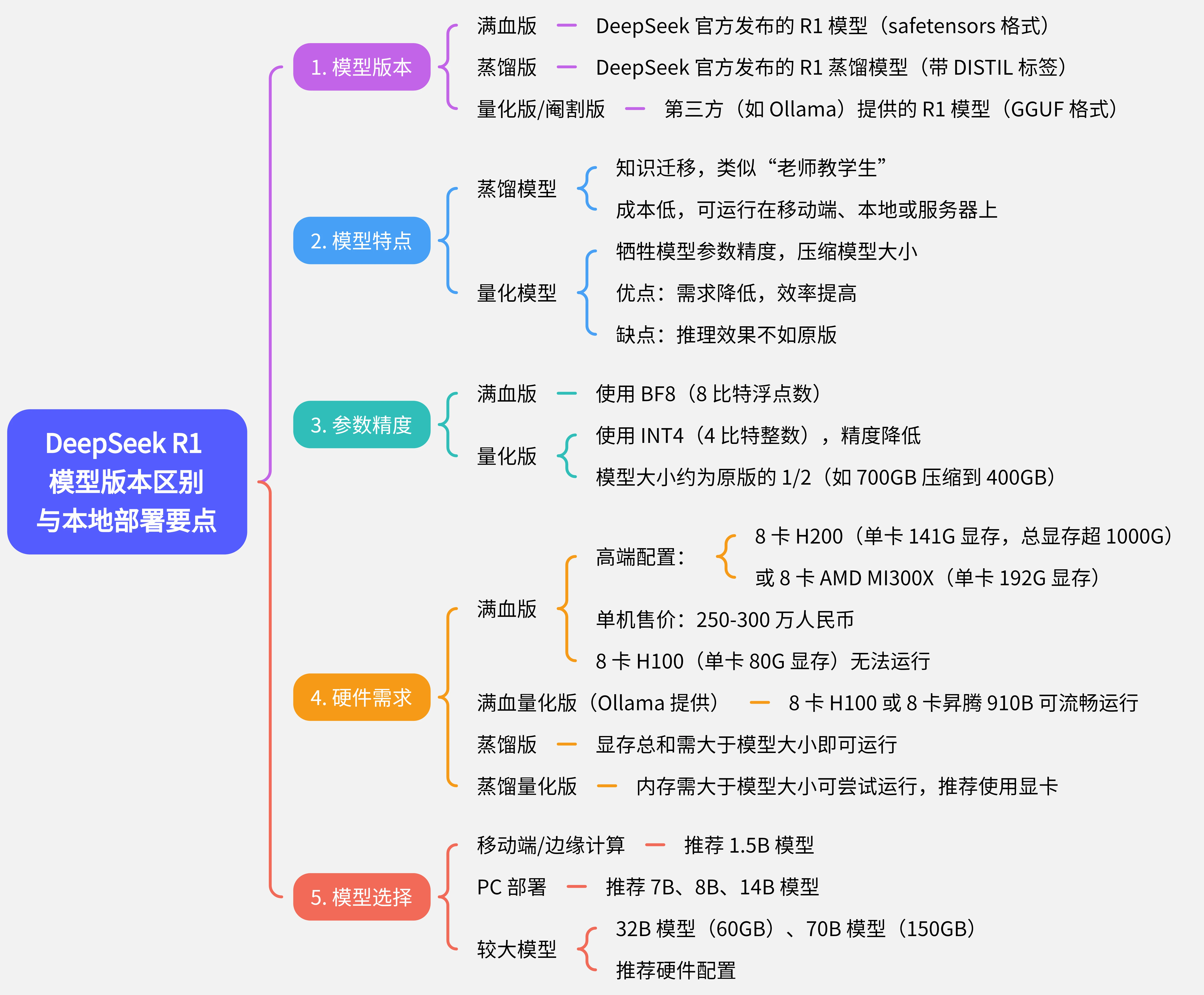
# DeepSeek R1部署配置
| 模型规模 | 量化等级推荐 | Apple Silicon (M系列) 配置要求 | x86 (AMD/Intel) 配置要求 | 适用场景 |
|---|---|---|---|---|
| 1.5B | 8-bit 或 4-bit | - 最低配置:M1 8GB RAM(纯CPU) - 建议配置:M1/M2 16GB RAM | - 最低配置:i5/R5 + 8GB RAM(无GPU) - 建议配置:核显(如Intel Iris Xe) + 16GB RAM | 轻量级对话、简单文本生成 |
| 7B | 6-bit 或 4-bit | - 最低配置:M1 16GB RAM(纯CPU) - 建议配置:M2/M3 24GB RAM(GPU加速) | - 最低配置:i7/R7 + 16GB RAM + 6GB显存(如RTX 3060) - 建议配置:RTX 4070 或同级显卡 + 32GB RAM | 通用对话、代码生成、文案创作 |
| 8B | 5-bit 或 4-bit | - 最低配置:M2 24GB RAM(GPU加速) - 建议配置:M3 Max 48GB RAM | - 最低配置:i9/R9 + 32GB RAM + 8GB显存(如RTX 3080) - 建议配置:RTX 4080 + 64GB RAM | 复杂推理、长文本生成 |
| 14B | 4-bit 或 3-bit | - 最低配置:M2 Ultra 64GB RAM(GPU加速) - 建议配置:M3 Max 128GB RAM | - 最低配置:RTX 4090 24GB显存 + 64GB RAM - 建议配置:双卡(如双RTX 4090) + 128GB RAM | 专业级数据分析、多轮复杂交互 |
| 32B | 3-bit 或 2-bit | - 仅限 M3 Ultra 192GB RAM(需量化优化) | - 最低配置:双RTX 6000 Ada 48GB显存 + 128GB RAM - 建议配置:服务器级硬件(如A100/H100) | 科研计算、大规模知识检索 |
| 70B | 2-bit 或 低精度优化 | - 不推荐,需云端协作 | - 仅限多卡服务器(如4x RTX 4090/A100) | 企业级私有化部署 |
| 671B | 需专用优化 | - 无法本地运行 | - 需分布式计算集群(如GPU农场) | 超大规模模型研究 |
- 模型规模: 模型规模越大,需要的内存越大。规模中的
B是Billion的缩写,表示 十亿。它用来描述模型参数的数量。 - 量化等级: 量化等级越高,模型精度越高,需要的内存越大。如
4-bit量化等级,表示模型参数使用4位精度存储。